Метод опорных векторов — один из самых популярных алгоритмов машинного обучения. Он эффективен и может быть обучен на ограниченных наборах данных. Но что это?
Содержание
- 1 Что такое машина опорных векторов (SVM)?
- 2 Как работает SVM?
- 3 SVM в машинном обучении
- 4 Как SVM работает с классификацией естественного языка
- 5 Создание SVM в Python
- 6 Преимущества SVM
- 7 Образовательные ресурсы
- 7.1 Введение в машины опорных векторов
- 7.2 Приложения для машин опорных векторов
- 7.3 Машины опорных векторов (информатика и статистика)
- 7.4 Обучение с ядрами
- 7.5 Машины опорных векторов с Sci-kit Learn
- 7.6 Машины опорных векторов в Python: концепции и код
- 7.7 Машинное обучение и искусственный интеллект: вспомогательные векторные машины в Python
- 7.8 Заключительные слова
- 7.9 Читайте также
Что такое машина опорных векторов (SVM)?
Машина опорных векторов — это алгоритм машинного обучения, который использует обучение с учителем для создания моделей для бинарной классификации. Это полный рот. В этой статье будет рассказано о SVM и о том, как он связан с обработкой естественного языка. Но сначала давайте проанализируем, как работает машина опорных векторов.
Как работает SVM?
Рассмотрим простую задачу классификации, в которой у нас есть данные с двумя признаками, k и i, и одним выходом — классификация красного или синего цвета. Мы можем нарисовать воображаемый набор данных, который выглядит так:
Учитывая такие данные, задача будет состоять в том, чтобы создать границу решения. Граница решения — это линия, которая разделяет два класса наших точек данных. Это тот же набор данных, но с границей решения:
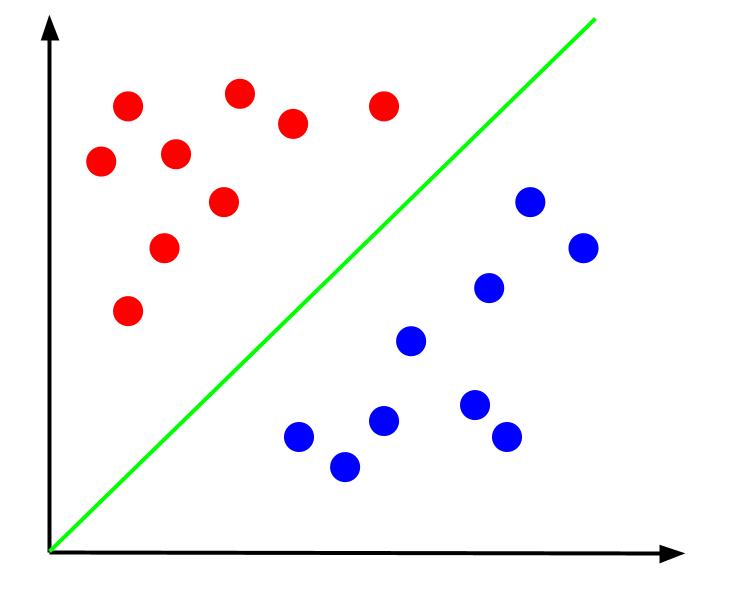
С помощью этой границы решения мы можем затем предсказать, к какому классу принадлежит точка данных, учитывая, где она находится по отношению к границе решения. Алгоритм машины опорных векторов создает наилучшую границу решения, которая будет использоваться для классификации точек.
Но что мы подразумеваем под границей наилучшего решения?
Можно утверждать, что наилучшей границей решения является та, которая максимально удалена от любого из опорных векторов. Опорные векторы — это точки данных любого класса, наиболее близкие к противоположному классу. Эти точки данных представляют самый высокий риск неправильной классификации из-за их близости к другому классу.

Таким образом, обучение машины опорных векторов включает в себя попытку найти линию, которая максимизирует разницу между опорными векторами.
Также важно отметить, что, поскольку граница решения расположена относительно опорных векторов, они являются единственными детерминантами положения границы решения. Поэтому другие точки данных являются избыточными. И поэтому для обучения нужны только опорные векторы.
В этом примере сформированная граница решения представляет собой прямую линию. Это только потому, что набор данных имеет только две функции. Когда набор данных имеет три функции, сформированная граница решения представляет собой плоскость, а не линию. А когда он имеет четыре или более функций, граница решения называется гиперплоскостью.
Нелинейные разделимые данные
В приведенном выше примере рассматриваются очень простые данные, которые при построении графика могут быть разделены линейной границей решения. Рассмотрим другой случай, когда данные отображаются следующим образом:

В этом случае разделение данных линией невозможно. Но мы можем создать еще одну функцию, z. И эту характеристику можно определить уравнением: z = k^2 + i^2. Мы можем добавить z в качестве третьей оси к плоскости, чтобы сделать ее трехмерной.
Когда мы смотрим на 3D-график под углом, так что ось x горизонтальна, а ось z вертикальна, мы получаем примерно такой вид:

Z-значение показывает, насколько далеко точка находится от начала координат относительно других точек на старой плоскости KSI. В результате синие точки ближе к началу координат имеют низкие значения z.
В то время как красные точки, расположенные дальше от начала координат, имели более высокие z-значения, их построение по отношению к их z-значениям дает нам четкую классификацию, которая может быть ограничена линейной границей решения, как показано на рисунке.
Это мощная идея, используемая в машинах опорных векторов. В более общем смысле это идея сопоставления измерений с большим количеством измерений, чтобы точки данных можно было разделить линейной границей. За это отвечают функции ядра. Существует множество функций ядра, таких как сигмовидная, линейная, нелинейная и RBF.
Чтобы сделать сопоставление этих функций более эффективным, SVM использует трюк ядра.
SVM в машинном обучении
Метод опорных векторов — один из многих алгоритмов, используемых в машинном обучении в дополнение к популярным алгоритмам, таким как деревья решений и нейронные сети. Его предпочитают, потому что он хорошо работает с меньшим объемом данных, чем другие алгоритмы. Обычно он используется для следующих целей:
- Классификация текста: классификация текстовых данных, таких как комментарии и обзоры, по одной или нескольким категориям.
- Распознавание лиц: анализ изображений для обнаружения лиц для выполнения таких действий, как добавление фильтров для дополненной реальности.
- Классификация изображений: машины опорных векторов могут эффективно классифицировать изображения по сравнению с другими подходами.
Проблема классификации текстов.
Интернет наполнен огромным количеством текстовых данных. Однако большая часть этих данных неструктурирована и не имеет тегов. Чтобы лучше использовать и понимать эти текстовые данные, необходима классификация. Примеры классификации текста:
- Когда твиты распределяются по темам, чтобы люди могли следить за интересующими их темами
- Когда электронное письмо классифицируется как социальное, рекламное или спам
- Когда комментарии классифицируются как ненавистные или непристойные на общедоступных форумах
Как SVM работает с классификацией естественного языка
Машина опорных векторов используется для классификации текста на тематический и неактуальный. Это достигается путем предварительного преобразования и представления текстовых данных в набор данных с несколькими функциями.
Один из способов сделать это — создать функции для каждого слова в наборе данных. Затем для каждой точки текстовых данных запишите, сколько раз появляется каждое слово. Предположим, что в наборе данных появляются уникальные слова; у вас будут функции в наборе данных.
Кроме того, вы предоставите классификации для этих точек данных. Хотя эти классификации помечены текстом, большинство реализаций SVM предполагают числовые метки.
Поэтому вам нужно будет преобразовать эти метки в числа перед тренировкой. Как только набор данных подготовлен, используя эти функции в качестве координат, вы можете использовать модель SVM для классификации текста.
Создание SVM в Python
Чтобы создать машину опорных векторов (SVM) в Python, вы можете использовать класс SVC из библиотеки sklearn.svm. Вот пример того, как вы можете использовать класс SVC для построения модели SVM в Python:
from sklearn.svm import SVC
# Load the dataset
X = ... y = ...
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19)
# Create an SVM model
model = SVC(kernel="linear")
# Train the model on the training data
model.fit(X_train, y_train)
# Evaluate the model on the test data
accuracy = model.score(X_test, y_test)
print("Accuracy: ", accuracy)
В этом примере мы сначала импортируем класс SVC из библиотеки sklearn.svm. Затем мы загружаем набор данных и разделяем его на обучающий и тестовый наборы.
Затем мы создаем модель SVM, создавая экземпляр объекта SVC и указав параметр ядра как «линейный». Затем мы обучаем модель на обучающих данных, используя метод подбора, и оцениваем модель на тестовых данных, используя метод оценки. Метод оценки возвращает точность модели, которую мы выводим на консоль.
Вы также можете указать другие параметры для объекта SVC, такие как параметр C, который управляет силой регуляризации, и параметр gamma, который управляет коэффициентом ядра для конкретных ядер.
Преимущества SVM
Вот список некоторых преимуществ использования машин опорных векторов (SVM):
- Эффективность: SVM обычно эффективны для обучения, особенно при большом количестве выборок.
- Устойчивость к шуму: SVM относительно устойчивы к шуму в обучающих данных, потому что они пытаются найти классификатор максимальной маржи, который менее чувствителен к шуму, чем другие классификаторы.
- Эффективность использования памяти: SVM требуют, чтобы в любой момент времени в памяти находилось только подмножество обучающих данных, что делает их более эффективными с точки зрения использования памяти, чем другие алгоритмы.
- Эффективность в многомерных пространствах: SVM по-прежнему могут работать хорошо, даже когда количество функций превышает количество выборок.
- Универсальность: SVM можно использовать как для задач классификации, так и для регрессии, и они могут обрабатывать различные типы данных, включая линейные и нелинейные данные.
Теперь давайте рассмотрим некоторые из лучших ресурсов для изучения машины опорных векторов (SVM).
Образовательные ресурсы
Введение в машины опорных векторов
Эта книга «Введение в машину опорных векторов» подробно и пошагово знакомит вас с методами обучения на основе ядра.
Это дает вам прочную основу для теории машины опорных векторов.
Приложения для машин опорных векторов
В то время как первая книга была посвящена теории машин опорных векторов, эта книга о приложениях машин опорных векторов фокусируется на их практическом применении.
В нем рассматривается, как SVM используются в обработке изображений, обнаружении закономерностей и компьютерном зрении.
Машины опорных векторов (информатика и статистика)
Цель этой книги о машинах опорных векторов (информатика и статистика) состоит в том, чтобы предоставить обзор принципов, лежащих в основе эффективности машин опорных векторов (SVM) в различных приложениях.
Авторы выделяют несколько факторов, которые способствуют успеху SVM, включая их способность хорошо работать с ограниченным числом настраиваемых параметров, их устойчивость к различным типам ошибок и аномалий, а также их эффективную вычислительную производительность по сравнению с другими методами.
Обучение с ядрами
«Обучение с ядрами» — это книга, которая знакомит читателей с машинами опорных векторов (SVM) и связанными с ними методами работы с ядром.
Он предназначен для того, чтобы дать читателям базовое понимание математики и знаний, необходимых им для начала использования алгоритмов ядра в машинном обучении. Книга призвана предоставить подробное, но доступное введение в SVM и методы ядра.
Машины опорных векторов с Sci-kit Learn
Этот онлайн-курс Support Vector Machines with Sci-kit Learn из сети проектов Coursera учит, как реализовать модель SVM с помощью популярной библиотеки машинного обучения Sci-Kit Learn.

Кроме того, вы изучите теорию SVM и определите их сильные и слабые стороны. Курс предназначен для начинающих и длится около 2,5 часов.
Машины опорных векторов в Python: концепции и код
Этот платный онлайн-курс по машинам опорных векторов в Python от Udemy включает до 6 часов видеоинструкций и поставляется с сертификатом.

Охватывает SVM и то, как их можно надежно реализовать в Python. Кроме того, он охватывает бизнес-приложения машин опорных векторов.
Машинное обучение и искусственный интеллект: вспомогательные векторные машины в Python
В этом курсе машинного обучения и искусственного интеллекта вы узнаете, как использовать машины опорных векторов (SVM) для различных практических приложений, включая распознавание изображений, обнаружение спама, медицинскую диагностику и регрессионный анализ.

Вы будете использовать язык программирования Python для реализации моделей машинного обучения для этих приложений.
Заключительные слова
В этой статье мы кратко узнали о теории, лежащей в основе машин опорных векторов. Мы узнали об их применении в машинном обучении и обработке естественного языка.
Мы также видели, как выглядит его реализация с помощью scikit-learn. Кроме того, мы говорили о практическом применении и преимуществах машин опорных векторов.
Хотя эта статья была только введением, рекомендуется использовать дополнительные ресурсы для более подробного ознакомления с методами опорных векторов. Учитывая, насколько они универсальны и эффективны, стоит понимать, что SVM следует разрабатывать специалистам по обработке и анализу данных и инженерам по машинному обучению.
Затем вы можете ознакомиться с лучшими моделями машинного обучения.