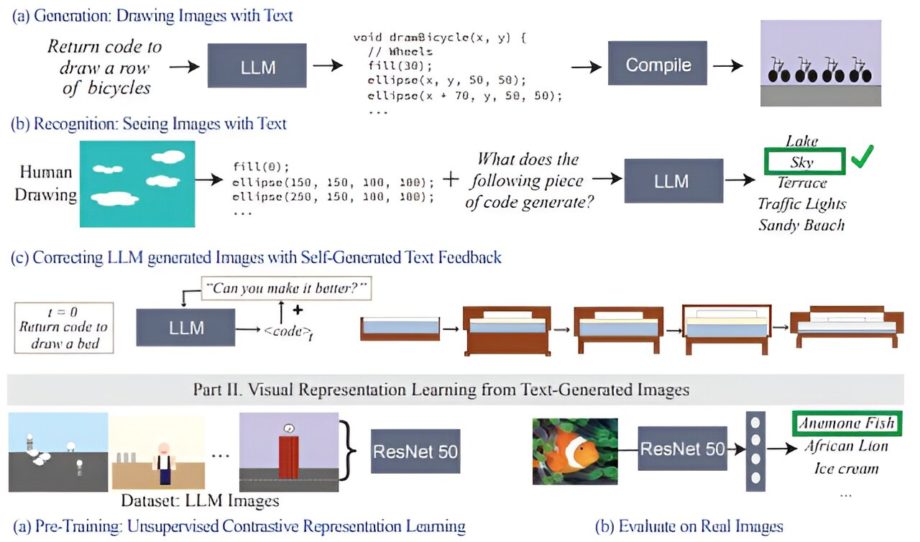
 способность писать код, который визуализирует сложные визуальные концепции (б) распознавание визуальных концепций из кода (в) исправление кода рендеринга с помощью только текстового самоанализа. обратная связь. II. Мы проверяем, могут ли LLM генерировать данные для обучения высокопроизводительной системы зрения, которую можно использовать для вынесения семантических суждений о естественных изображениях. Фото: arXiv (2024). DOI: 10.48550/arxiv.2401.01862.")
Проверка зрения для студентов LLM. I. Проверка визуального знания языковых моделей. Мы предлагаем набор тестов для проверки зрительных способностей языковых моделей, которые включают в себя (а) способность писать код, который визуализирует сложные визуальные концепции (б) распознавание визуальных концепций из кода (в) исправление кода рендеринга с помощью только текстового самоанализа. обратная связь. II. Мы проверяем, могут ли LLM генерировать данные для обучения высокопроизводительной системы зрения, которую можно использовать для вынесения семантических суждений о естественных изображениях. Кредит: arXiv (2024). DOI: 10.48550/arxiv.2401.01862.
Вы, вероятно, слышали, что изображение стоит тысячи слов, но может ли модель большого языка (LLM) получить изображение, если оно никогда раньше не видело изображений?
Как оказалось, языковые модели, обучающиеся исключительно на тексте, имеют четкое представление о визуальном мире. Они могут писать код рендеринга изображений для создания сложных сцен с интригующими объектами и композициями — и даже если эти знания не используются должным образом, LLM могут улучшить свои изображения. Исследователи из Лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института (CSAIL) наблюдали это, когда предлагали языковым моделям самостоятельно корректировать свой код для различных изображений, при этом системы улучшали свои простые рисунки с каждым запросом.
Визуальные знания об этих языковых моделях получены из того, как такие понятия, как формы и цвета, описываются в Интернете, будь то на языке или в коде. Когда им дают такое указание, как «нарисовать попугая в джунглях», пользователи запускают LLM, чтобы обдумать то, что они читали в описаниях ранее.
Чтобы оценить, насколько обширными визуальными знаниями обладают LLM, команда CSAIL провела «проверку зрения» для LLM: используя свой «набор данных о зрительных способностях», они проверили способности моделей рисовать, распознавать и самостоятельно корректировать эти понятия. Собрав каждый окончательный вариант этих иллюстраций, исследователи обучили систему компьютерного зрения, которая определяет содержание реальных фотографий.
Их работы опубликованы на arXiv сервер препринтов.
«По сути, мы тренируем систему зрения, не используя напрямую какие-либо визуальные данные», — говорит Тамар Ротт Шахам, соавтор исследования и постдок в CSAIL Массачусетского технологического института по электротехнике и информатике (EECS). «Наша команда запросила языковые модели, чтобы написать коды рендеринга изображений для генерации данных для нас, а затем обучила систему зрения оценивать естественные изображения. Нас вдохновил вопрос о том, как визуальные концепции представляются с помощью других средств, таких как текст. визуальные знания, LLM могут использовать код как точку соприкосновения между текстом и изображением».
Чтобы создать этот набор данных, исследователи сначала запросили модели, чтобы сгенерировать код для различных форм, объектов и сцен. Затем они скомпилировали этот код для визуализации простых цифровых иллюстраций, таких как ряд велосипедов, показав, что студенты LLM достаточно хорошо понимают пространственные отношения, чтобы рисовать двухколесные транспортные средства в горизонтальном ряду. Другой пример: модель создала торт в форме автомобиля, объединив две случайные концепции. Языковая модель также создала светящуюся лампочку, что указывает на ее способность создавать визуальные эффекты.
«Наша работа показывает, что когда вы запрашиваете LLM (без мультимодального предварительного обучения) для создания изображения, он знает гораздо больше, чем кажется», — говорит соавтор, доктор философии EECS. студентка и член CSAIL Пратюша Шарма. «Предположим, вы попросили его нарисовать стул. Модель знает другие вещи об этом предмете мебели, которые она, возможно, не сразу отобразила, поэтому пользователи могут запрашивать модель, чтобы улучшить визуальный результат, который она создает с каждой итерацией. Удивительно, но модель может итеративно обогатить рисунок, значительно улучшив код рендеринга».
Исследователи собрали эти иллюстрации, которые затем были использованы для обучения системы компьютерного зрения, способной распознавать объекты на реальных фотографиях (несмотря на то, что они никогда раньше их не видели). Используя эти синтетические текстовые данные в качестве единственной контрольной точки, система превосходит другие процедурно сгенерированные наборы данных изображений, которые были обучены с использованием подлинных фотографий.
Команда CSAIL считает, что объединение скрытых визуальных знаний LLM с художественными возможностями других инструментов искусственного интеллекта, таких как диффузионные модели, также может быть полезным. Таким системам, как Midjourney, иногда не хватает ноу-хау для последовательной настройки мелких деталей изображения, что затрудняет обработку таких запросов, как уменьшение количества изображенных автомобилей или размещение одного объекта позади другого. Если бы LLM заранее набросал запрошенное изменение для модели распространения, итоговое редактирование могло бы быть более удовлетворительным.
Ирония, как признают Ротт Шахам и Шарма, заключается в том, что студенты магистратуры иногда не могут распознать те же концепции, которые они могут нарисовать. Это стало ясно, когда модели неправильно идентифицировали воссозданные человеком изображения в наборе данных. Столь разнообразные представления визуального мира, вероятно, вызвали заблуждения языковых моделей.
Хотя модели с трудом воспринимали эти абстрактные изображения, они демонстрировали креативность, каждый раз рисуя одни и те же концепции по-разному. Когда исследователи несколько раз просили студентов LLM нарисовать такие понятия, как клубника и игровые автоматы, они создавали изображения под разными углами, с разными формами и цветами, намекая, что модели могут иметь реальные мысленные образы визуальных концепций (вместо того, чтобы перечислять примеры, которые они видели раньше).
Команда CSAIL считает, что эта процедура может стать основой для оценки того, насколько хорошо генеративная модель ИИ может обучать систему компьютерного зрения. Кроме того, исследователи стремятся расширить круг задач, для решения которых они бросают вызов языковым моделям. Что касается своего недавнего исследования, группа MIT отмечает, что у них нет доступа к обучающему набору программ LLM, которые они использовали, что затрудняет дальнейшее изучение происхождения их визуальных знаний. В будущем они намерены изучить возможность обучения еще более совершенной модели видения, позволив LLM работать напрямую с ней.
К Шарме и Ротту Шахаму в работе присоединились бывшая членская организация CSAIL Стефани Фу и доктор философии EECS. студенты Манель Барадад, Адриан Родригес-Муньос и Шивам Дуггал, которые являются филиалами CSAIL; а также доцент Массачусетского технологического института Филипп Изола и профессор Антонио Торральба.
На этой неделе они представят свою статью на конференции IEEE/CVF по компьютерному зрению и распознаванию образов.
Больше информации:
Пратюша Шарма и др. «Проверка зрения языковых моделей», arXiv (2024). DOI: 10.48550/arxiv.2401.01862.
arXiv
Эта история переиздана благодаря MIT News (web.mit.edu/newsoffice/), популярному сайту, на котором освещаются новости об исследованиях, инновациях и преподавании MIT.
Цитирование: Использование иллюстраций для обучения системы компьютерного зрения без изображений распознаванию реальных фотографий (17 июня 2024 г.), получено 18 июня 2024 г. с https://techxplore.com/news/2024-06-image-free-vision-real-photos. .html
Этот документ защищен авторским правом. За исключением любых добросовестных сделок в целях частного изучения или исследования, никакая часть не может быть воспроизведена без письменного разрешения. Содержимое предоставлено исключительно в информационных целях.