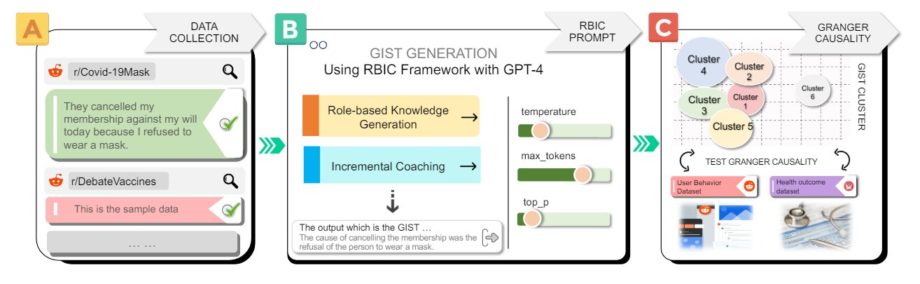
, структуру подсказок модели большого языка (LLM). (A) Сбор наборов данных Reddit, ориентированных на сообщества, известные своим противодействием медицинским практикам, связанным с COVID-19. (B) Руководствуясь теорией нечетких следов, мы представляем новую структуру LLM, называемую ролевым инкрементным коучингом (RBIC), для извлечения пар причинно-следственных связей и формулирования связных сути, фиксирующих причинно-следственные связи в текстах. (C) Тесты на причинно-следственную связь по Грейнджеру и анализ данных показывают влияние этих основных моментов на участие сообщества и результаты национального здравоохранения, такие как уровень вакцинации и уровень госпитализации. Фото: arXiv (2024). DOI: 10.48550/arxiv.2403.00994.")
Наше исследование эмпирически связывает разговоры в социальных сетях с результатами национального здравоохранения, связанными с COVID-19. Мы представляем ролевое инкрементальное обучение (RBIC), структуру подсказок модели большого языка (LLM). (A) Сбор наборов данных Reddit, ориентированных на сообщества, известные своим противодействием медицинским практикам, связанным с COVID-19. (B) Руководствуясь теорией нечетких следов, мы представляем новую структуру LLM, называемую ролевым инкрементным коучингом (RBIC), для извлечения пар причинно-следственных связей и формулирования связных сути, фиксирующих причинно-следственные связи в текстах. (C) Тесты на причинно-следственную связь по Грейнджеру и анализ данных показывают влияние этих основных моментов на участие сообщества и результаты национального здравоохранения, такие как уровень вакцинации и уровень госпитализации. Кредит: arXiv (2024). DOI: 10.48550/arxiv.2403.00994.
«Палки и камни могут сломать мне кости», — гласит старая пословица. «Но слова никогда не причинят мне вреда». Скажите это Евгении Ро, доценту кафедры компьютерных наук, и она покажет вам обширные данные, доказывающие обратное.
Ее лаборатория «Общество + искусственный интеллект и язык» показала, что
Теперь исследовательская группа Ро в Инженерном колледже обратилась к другому вопросу: какое влияние риторика в социальных сетях оказала на уровень заражения и смертности от Covid-19 в Соединенных Штатах, и какой урок могут извлечь из этого политики и представители общественного здравоохранения?
«Многие исследования просто описывают то, что происходит в Интернете. Часто они не показывают прямой связи с поведением в реальной жизни», — сказал Ро. «Но есть реальный способ связать поведение в Интернете с принятием решений в автономном режиме».
Содержание
Причина и следствие
Во время пандемии COVID-19 социальные сети стали местом массового сбора противников рекомендаций общественного здравоохранения, таких как ношение масок, социальное дистанцирование и вакцинация. Растущая дезинформация привела к повсеместному игнорированию профилактических мер и привела к резкому росту заболеваемости, переполнению больниц, нехватке медицинских работников, предотвратимой смертности и экономическим потерям.
Согласно исследованию 2022 года, опубликованному в Йельском журнале биологии и медицины, за месячный период с ноября по декабрь 2021 года среди непривитых пациентов было зарегистрировано более 692 000 предотвратимых госпитализаций. Только эти госпитализации обошлись в ошеломляющие 13,8 миллиарда долларов.
В исследовании команда Ро, в том числе доктор философии. Студент Сяохань Дин разработал методику, которая обучила чат-бота GPT-4 анализировать сообщения в нескольких запрещенных дискуссионных группах субреддита, которые выступали против мер профилактики COVID-19. По словам Ро, команда сосредоточилась на Reddit, потому что его данные были доступны. Многие другие социальные сети запретили сторонним исследователям использовать свои данные. Исследование опубликовано на сайте arXiv сервер препринтов.
Работа Ро основана на концепции социальных наук под названием «Теория нечетких следов», впервые разработанной Валери Рейна, профессором психологии Корнелльского университета и соавтором проекта Технологического института Вирджинии.
Рейна показала, что люди лучше усваивают и запоминают информацию, когда она выражена в причинно-следственной связи, а не просто в виде заученной информации. Это справедливо, даже если информация неточна или подразумеваемая связь слаба. Рейна называет эту причинно-следственную конструкцию «сущностью».
Исследователи работали над ответом на четыре фундаментальных вопроса, связанных с сутью социальных сетей:
- Как мы можем эффективно прогнозировать суть дискурса в социальных сетях в национальном масштабе?
- Какие основные положения характеризуют то, как и почему люди выступают против практики общественного здравоохранения, связанной с COVID-19, и как эти основные положения меняются с течением времени в зависимости от ключевых событий?
- Смогут ли шаблоны сути предсказать закономерности онлайн-взаимодействия среди пользователей запрещенных субреддитов, которые выступают против практики здравоохранения, связанной с COVID-19?
- Могут ли основные закономерности в значительной степени предсказать тенденции в национальных показателях здоровья?
Недостающее звено
Команда Ро использовала методы подсказок в больших языковых моделях (LLM) — типе программы искусственного интеллекта (ИИ) — а также расширенную статистику для поиска и последующего отслеживания этих суть в запрещенных группах субреддита. Затем модель сравнила их с контрольными показателями COVID-19, такими как уровень заражения, госпитализация, смертность и соответствующие заявления о государственной политике.
Результаты показывают, что сообщения в социальных сетях, связывающие причину, например «Я получил вакцину от COVID», с эффектом, например «С тех пор я чувствую себя как смерть», быстро проявлялись в убеждениях людей и влияли на них. их офлайн-решения о здоровье. Фактически, общее количество и новых ежедневных случаев заболевания COVID-19 в США можно в значительной степени предсказать по объему сообщений в запрещенных группах на Reddit.
Это первое исследование искусственного интеллекта, которое эмпирически связывает лингвистические модели социальных сетей с реальными тенденциями общественного здравоохранения, подчеркивая потенциал этих крупных языковых моделей для выявления критических моделей онлайн-дискуссии и указания на более эффективные стратегии коммуникации в области общественного здравоохранения.
«Это исследование решает сложную проблему: как связать когнитивные строительные блоки смысла, которые люди на самом деле используют, с потоком информации через социальные сети и с миром последствий для здоровья», — сказала Рейна. «Эта система LLM, основанная на подсказках, которая определяет суть в масштабе, имеет множество потенциальных приложений, которые могут способствовать улучшению здоровья и благополучия».
Большие данные, большое влияние
Ро сказала, что надеется, что это исследование побудит других исследователей применить эти методы для решения важных вопросов. С этой целью код, используемый в этом проекте, будет доступен бесплатно, когда статья будет опубликована в Материалы конференции Ассоциации вычислительной техники по человеческому фактору в вычислительных системах. В документе также сравнивается стоимость различных способов, с помощью которых исследователи могут анализировать большие наборы данных и делать значимые выводы с меньшими затратами. Команда представит свои выводы 11–16 мая в Гонолулу, Гавайи.
За пределами академических кругов Ро выразила надежду, что эта работа побудит платформы социальных сетей и других заинтересованных сторон найти альтернативы удалению или запрету групп, обсуждающих спорные темы.
«Простой запрет людей в онлайн-сообществах, особенно в местах, где они уже обмениваются и изучают медицинскую информацию, может привести к тому, что они еще глубже погрузится в теории заговора и вынудят их перейти на платформы, которые вообще не модерируют контент», — сказал Ро. «Я надеюсь, что это исследование поможет понять, как компании социальных сетей работают рука об руку с чиновниками и организациями общественного здравоохранения, чтобы лучше вовлекать и понимать, что происходит в сознании общественности во время кризисов в области общественного здравоохранения».
Больше информации:
Сяохан Дин и др., «Использование моделей большого языка на основе подсказок: прогнозирование решений и результатов в области здравоохранения при пандемии с помощью языка социальных сетей», arXiv (2024). DOI: 10.48550/arxiv.2403.00994.
arXiv
Предоставлено Технологическим институтом штата Вирджиния
Цитирование: Исследование отслеживает инфекционную языковую эпидемию (11 мая 2024 г.), получено 12 мая 2024 г. с https://medicalxpress.com/news/2024-05-infectious-language-epidemic.html.
Этот документ защищен авторским правом. За исключением любых добросовестных сделок в целях частного изучения или исследования, никакая часть не может быть воспроизведена без письменного разрешения. Содержимое предоставлено исключительно в информационных целях.