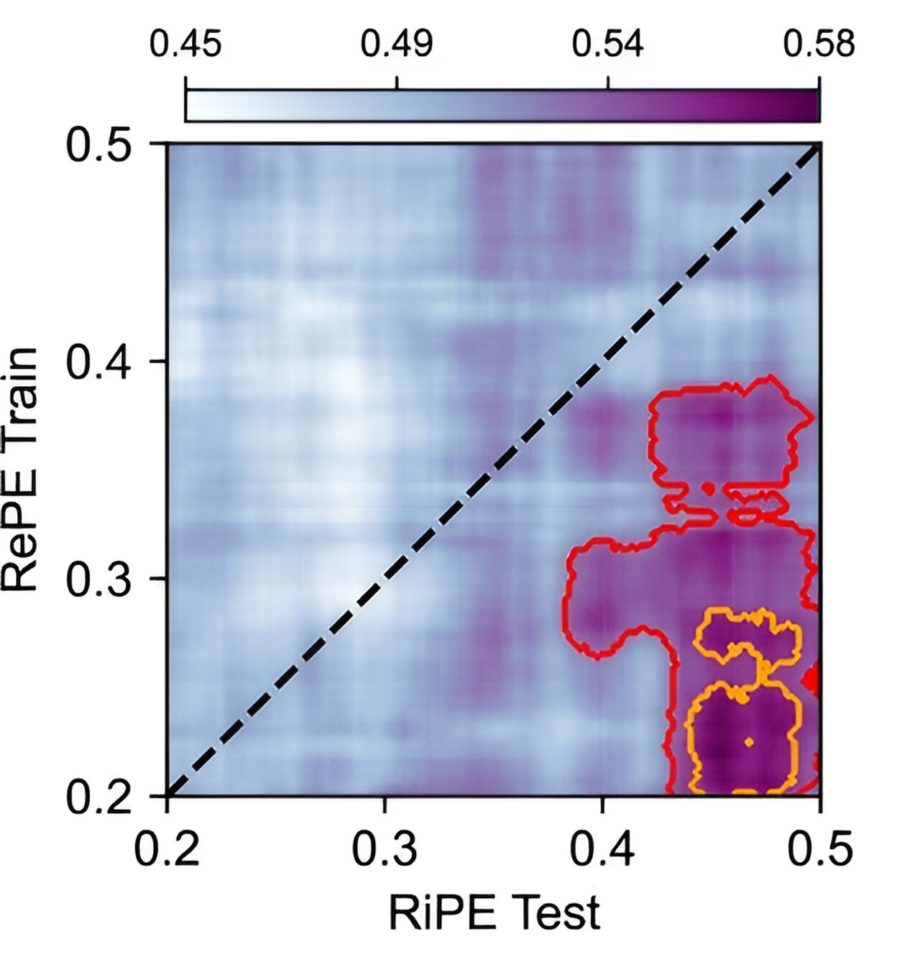
 перекрестного декодирования RePE в RiPE с использованием сигнала потенциала локального поля в передней островковой доле. Очерченные области существенно отличаются от случайных. Фото: Nature Communications (2024 г.). DOI: 10.1038/s41467-024-46094-1")
Нейронная активность в области мозга, называемой передней островковой частью, может использовать представление RePE для последующего декодирования RiPE. На рисунке показано время (в секундах после представления информации о результате) перекрестного декодирования RePE в RiPE с использованием сигнала потенциала локального поля в передней островковой доле. Очерченные области существенно отличаются от случайных. Кредит: Природные коммуникации (2024). DOI: 10.1038/s41467-024-46094-1
Представьте, что вы рассматриваете возможность покупки акций компании. Вы знаете, какова его текущая стоимость, и подозреваете, что можете получить значительную прибыль от своих инвестиций. Но эта акция очень волатильна: несколько дней вверх, несколько дней вниз. Да, вы можете заработать много денег, но вы также можете много потерять. Здесь есть очевидная награда, но и большой риск.
Многие решения такие. Банка томатной пасты, распродажа в продуктовом магазине, — фантастическая сделка, если она не испортилась, но если она испортилась, вы выбросили свои деньги.
Подобные решения — классическая ситуация, рассматриваемая экономистами. Новое исследование лаборатории Джона О'Доэрти, профессора нейронауки принятия решений Флетчера Джонса Калифорнийского технологического института, направлено на то, чтобы понять, как мозг реализует такого рода решения, путем тестирования вычислительной модели, которая предполагает, как представления о вознаграждении и риске строятся на основе опыта.
Нейронная обработка вознаграждения и риска ранее изучалась в Калифорнийском технологическом институте с помощью метода функциональной магнитно-резонансной томографии (фМРТ), который измеряет изменения кровотока внутри мозга. Исследователи обнаружили, что область мозга, называемая передней островковой частью, активируется, когда люди оценивают риск и неопределенность процесса.
В новом исследовании электроды, имплантированные глубоко в мозг пациентов (для несвязанных с терапевтическими целями), позволили О'Доэрти и его команде получить еще более точные измерения активности мозга во время принятия решений.
В ходе работы выяснилось, что, как и ожидалось, первой появляется так называемая ошибка прогнозирования вознаграждения (разница между ожидаемым значением и наблюдаемым значением), а за ней следует ошибка прогнозирования риска (разница между ожидаемой неопределенностью и фактической неопределенностью). которая основывалась на тех же нейронных процессах, что и ошибка прогнозирования вознаграждения. Оба сигнала были обнаружены в передней островковой оболочке.
Эти результаты позволяют предположить, что ошибка прогнозирования вознаграждения используется для расчета ошибки прогнозирования риска, которую затем можно использовать для обучения оценке рискованности, что является необходимым руководством для принятия решений.
Эти результаты были опубликованы в выпуске журнала от 9 марта 2024 г. Природные коммуникации.
Винсент Мэн, старший научный сотрудник в области нейробиологии и соавтор статьи, объясняет: «ФМРТ отлично показывает нам, где в мозгу что-то происходит, но ее возможности ограничены в том, что касается информации о том, когда что-то происходит. по крайней мере, в тех быстрых временных масштабах, в которых, как мы думаем, разворачиваются эти нейронные процессы».
Для этого исследования пациенты, проходившие обследование на эпилепсию, были набраны в больницах и клиниках Университета Айовы. Чтобы контролировать судорожную активность, этим людям имплантировали электроды глубоко в ключевые области мозга, в том числе в переднюю островковую долю, что позволило исследователям обнаруживать нервную активность в микросекундном масштабе времени, что невозможно с помощью фМРТ.
Затем участники играли в очень простую карточную игру, используя 10 игральных карт, пронумерованных от туза до 10, причем туз считается за единицу. Их попросили незаметно предсказать, будет ли вторая карта выше или ниже по ценности, чем первая. Поскольку ни одна карта не была видна, это всегда была совершенно случайная догадка.
После того, как была показана первая карточка, участники получали некоторую информацию о том, насколько точным может быть их предположение. Например, если бы они предсказали, что вторая карта будет младше, а первая карта была бы 10, они бы сразу поняли, что их предположение верно. Если бы первая карта была тузом, они бы знали, что ошибались. Но если первой картой была пятёрка, исход оставался неопределенным до тех пор, пока не была раскрыта вторая карта.
«По сути, с помощью этой игры мы рисуем дугу от отсутствия неопределенности к максимальной неопределенности», — объясняет Мэн, работающий в лаборатории О'Догерти. «Вычислительная модель предсказывает, что вы делаете одно вычисление и формируете ожидание относительно риска. Когда вы видите вторую карту, происходит второе вычисление для оценки ожидаемого риска».
Вычисления, используемые для этих прогнозов, идентифицируются как ошибка прогнозирования вознаграждения (RePE) — процесс обновления между ожидаемым вознаграждением и наблюдаемым вознаграждением (фактическая вытянутая карта) и ошибка прогнозирования риска (RiPE) — процесс оценки ожидаемый риск по отношению к наблюдаемому риску.
Активность, обнаруженная в передней островковой части во время этих игр, демонстрировала именно этот двухэтапный процесс после отображения второй карты: сначала оценка прогнозирования вознаграждения, а затем оценка ошибки прогнозирования риска.
«Мы проверяем теоретическую идею о взаимосвязи между вознаграждением и риском и о том, как они связаны друг с другом», — говорит Мэн. «Тот факт, что нейронная сигнатура согласуется с теорией, хорош; это обосновывает теорию».
О'Догерти добавляет: «Определение того, как мозг генерирует такого рода вычисления, может помочь нам в конечном итоге построить более точные модели того, как мозг обучается и принимает решения, что может быть полезно не только для понимания того, как мозг работает в целом, но также, потенциально, для понимания того, как эти процессы могут пойти не так при таких заболеваниях, как пристрастие к азартным играм, зависимость или другие психические расстройства».
Больше информации:
Винсент Мэн и др., Временно организованные представления вознаграждения и риска в человеческом мозге, Природные коммуникации (2024). DOI: 10.1038/s41467-024-46094-1
Предоставлено Калифорнийским технологическим институтом
Цитирование: Когда мозг обрабатывает вознаграждение и риск? Нейробиологи тестируют вычислительную модель (21 марта 2024 г.), полученную 21 марта 2024 г. с https://medicalxpress.com/news/2024-03-brain-reward-neuroscientists.html.
Этот документ защищен авторским правом. За исключением любых добросовестных сделок в целях частного изучения или исследования, никакая часть не может быть воспроизведена без письменного разрешения. Содержимое предоставлено исключительно в информационных целях.