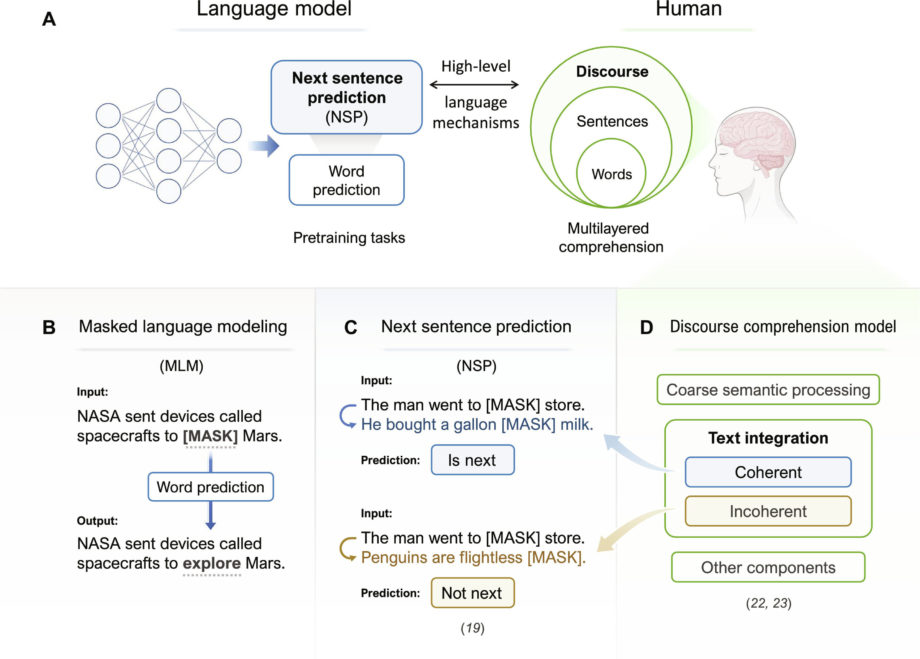
 Люди объединяют слова и предложения для достижения полного понимания дискурса. В LLM задача NSP, предложенная BERT, может служить вычислительным отчетом о понимании человеческого дискурса. (B) Иллюстрация задачи MLM. (C) Иллюстрация задачи НСП и ее соответствия модели Мэйсона и Справедливости. (D) Иллюстрация нейрокогнитивной модели обработки дискурса Мэйсона и Джаста. Фото: Достижения науки (2024 г.). DOI: 10.1126/sciadv.adn7744.")
НСП как вычислительный подход к пониманию дискурса. (А) Люди объединяют слова и предложения для достижения полного понимания дискурса. В LLM задача NSP, предложенная BERT, может служить вычислительным отчетом о понимании человеческого дискурса. (B) Иллюстрация задачи MLM. (C) Иллюстрация задачи НСП и ее соответствия модели Мэйсона и Справедливости. (D) Иллюстрация нейрокогнитивной модели обработки дискурса Мэйсона и Джаста. Кредит: Достижения науки (2024). DOI: 10.1126/sciadv.adn7744.
В связи с тем, что в последние годы генеративный искусственный интеллект (GenAI) изменил ландшафт социального взаимодействия, в центре внимания оказались большие языковые модели (LLM), которые используют алгоритмы глубокого обучения для обучения платформ GenAI обработке языка.
Недавнее исследование, проведенное Гонконгским политехническим университетом (PolyU), показало, что LLM работают больше как человеческий мозг, когда их обучают таким же образом, как люди обрабатывают речь, что привело к важным открытиям в исследованиях мозга и разработке моделей искусственного интеллекта.
Современные LLM в основном полагаются на один тип предварительного обучения — контекстное предсказание слов. Эта простая стратегия обучения достигла удивительного успеха в сочетании с огромными данными обучения и параметрами модели, как показывают популярные LLM, такие как ChatGPT.
Недавние исследования также показывают, что предсказание слов в LLM может служить правдоподобной моделью того, как люди обрабатывают язык. Однако люди не просто предсказывают следующее слово, но и интегрируют информацию высокого уровня в понимание естественного языка.
Исследовательская группа под руководством профессора Ли Пина, декана факультета гуманитарных наук и профессора гуманитарных наук и технологий Фонда Син Вай Кин Полиуниверситета, исследовала задачу прогнозирования следующего предложения (NSP), которая имитирует один центральный процесс понимания на уровне дискурса. в человеческом мозге, чтобы оценить, является ли пара предложений связной, в предварительную тренировку модели и исследовал корреляцию между данными модели и активацией мозга.
Исследование было недавно опубликовано в журнале Достижения науки.
Исследовательская группа обучила две модели: одну с усовершенствованием NSP, а другую — без; оба также научились предсказывать слова. Данные функциональной магнитно-резонансной томографии (фМРТ) были собраны у людей, читающих связные или несвязные предложения. Исследовательская группа изучила, насколько близко закономерности каждой модели совпадают с закономерностями мозга, полученными при помощи фМРТ.
Было ясно, что обучение с NSP дает свои преимущества. Модель с NSP гораздо лучше соответствовала активности человеческого мозга во многих областях, чем модель, обученная только предсказанию слов. Его механизм также хорошо согласуется с устоявшимися нейронными моделями понимания человеческого дискурса.
Результаты дают новое представление о том, как наш мозг обрабатывает полноценный дискурс, например разговоры. Например, части правого полушария мозга, а не только левого, помогали понимать более длительную речь. Модель, обученная с помощью NSP, также могла лучше предсказать, насколько быстро кто-то читает, показав, что имитация понимания дискурса с помощью NSP помогает ИИ лучше понимать людей.
Недавние LLM, в том числе ChatGPT, полагались на значительное увеличение обучающих данных и размера модели для достижения более высокой производительности. Профессор Ли Пин сказал: «Есть ограничения в том, чтобы просто полагаться на такое масштабирование. Достижения также должны быть направлены на то, чтобы сделать модели более эффективными, полагаясь на меньшее, а не на большее количество данных. Наши результаты показывают, что разнообразные задачи обучения, такие как NSP, могут улучшить LLM. быть более похожим на человека и потенциально ближе к человеческому интеллекту».
«Что еще более важно, результаты показывают, как нейрокогнитивные исследователи могут использовать LLM для изучения языковых механизмов нашего мозга более высокого уровня. Они также способствуют взаимодействию и сотрудничеству между исследователями в области ИИ и нейрокогниции, что приведет к будущим исследованиям в области искусственного интеллекта. исследования мозга, а также искусственный интеллект, вдохновленный мозгом».
Больше информации:
Шаоюнь Ю и др., «Предсказание следующего предложения (не слова) в больших языковых моделях: что соответствие модели и мозга говорит нам о понимании дискурса», Достижения науки (2024). DOI: 10.1126/sciadv.adn7744.
Предоставлено Гонконгским политехническим университетом.
Цитирование: Улучшение моделей большого языка ИИ помогает им лучше согласовываться с деятельностью человеческого мозга (27 мая 2024 г.), получено 28 мая 2024 г. с https://medicalxpress.com/news/2024-05-ai-large-language-align-human.html.
Этот документ защищен авторским правом. За исключением любых добросовестных сделок в целях частного изучения или исследования, никакая часть не может быть воспроизведена без письменного разрешения. Содержимое предоставлено исключительно в информационных целях.