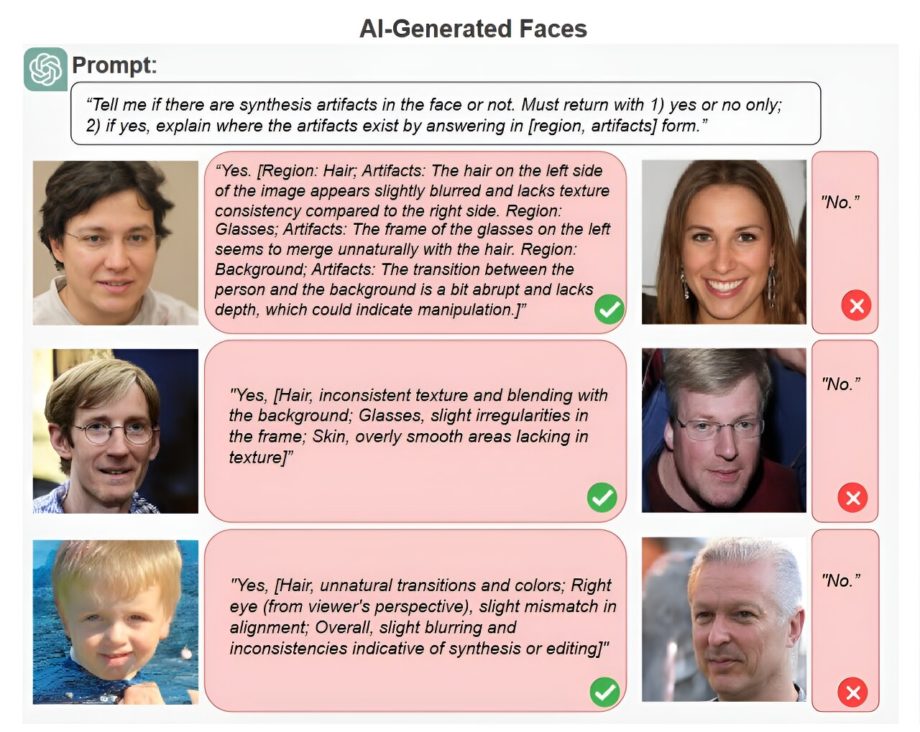

Пример анализа изображений deepfake с помощью ChatGPT. Большая языковая модель оказалась менее точной, чем современные детекторы deepfake, но впечатлила исследователей своей способностью объяснять свой анализ простым языком. Кредит: Университет в Буффало
Когда большинство людей думают об искусственном интеллекте, они, вероятно, думают о ChatGPT и deepfakes и беспокоятся о них. Текст и изображения, сгенерированные ИИ, доминируют в наших лентах социальных сетей и на других веб-сайтах, которые мы посещаем, иногда без нашего ведома, и часто используются для распространения недостоверной и вводящей в заблуждение информации.
Но что, если модели генерации текста, такие как ChatGPT, действительно смогут обнаруживать дипфейковые изображения?
Исследовательская группа под руководством Университета Буффало применила большие языковые модели (LLM), в том числе ChatGPT OpenAI и Gemini от Google, для обнаружения дипфейков человеческих лиц. Их исследование, представленное на прошлой неделе на конференции IEEE/CVF по компьютерному зрению и распознаванию образов, показало, что производительность LLM отстает от производительности современных алгоритмов обнаружения дипфейков, но их обработка естественного языка может фактически сделать их более эффективными. практический инструмент обнаружения в будущем.
Исследование также опубликовано на arXiv сервер препринтов.
«Что отличает LLM от существующих методов обнаружения, так это способность объяснять свои результаты понятным для человека способом, например, идентифицировать неправильную тень или несовпадающую пару сережек», — говорит ведущий автор исследования Сивэй Лю, доктор философии. , профессор инноваций SUNY Empire на факультете компьютерных наук и инженерии Школы инженерии и прикладных наук Университетского университета. «LLM не были разработаны или обучены для обнаружения дипфейков, но их семантические знания делают их хорошо подходящими для этого, поэтому мы ожидаем увидеть больше усилий в направлении этого приложения».
В исследовании участвуют Университет Олбани и Китайский университет Гонконга в Шэньчжэне.
Содержание
Как языковые модели понимают изображения
Обученный на большей части доступного в Интернете текста (около 300 миллиардов слов), ChatGPT находит статистические закономерности и взаимосвязи между словами для генерации ответов.
Последние версии ChatGPT и других LLM также могут анализировать изображения. Эти мультимодальные LLM используют большие базы данных фотографий с подписями для поиска связей между словами и изображениями.
«Люди тоже делают то же самое. Будь то знак остановки или вирусный мем, мы постоянно присваиваем изображениям семантическое описание», — говорит первый автор исследования Шан Джай, помощник директора лаборатории судебной экспертизы UB Media. «Таким образом, изображения становятся собственным языком».
Команда Media Forensics Lab решила проверить, может ли GPT-4 со зрением (GPT-4V) и Gemini 1.0 различать реальные лица и лица, сгенерированные ИИ. Они дали ему тысячи изображений как реальных, так и поддельных лиц и попросили его выявить любые потенциальные признаки манипуляции или синтетические артефакты.
Преимущества ChatGPT
ChatGPT показал точность в 79,5% случаев при обнаружении синтетических артефактов на изображениях, полученных с помощью скрытой диффузии, и в 77,2% случаев на изображениях, полученных с помощью StyleGAN.
«Это сопоставимо с более ранними методами обнаружения дипфейков, поэтому при должном оперативном руководстве ChatGPT может довольно неплохо справляться с обнаружением изображений, созданных ИИ», — говорит Лю, который также является содиректором Центра информационной целостности UB.
Что еще более важно, ChatGPT может объяснять свои решения простым языком. Когда ей предоставили фотографию мужчины в очках, сгенерированную искусственным интеллектом, модель правильно отметила, что «волосы на левой стороне изображения слегка размыты» и «переход между человеком и фоном немного резкий и ему не хватает глубины». «
«Существующие модели обнаружения дипфейков сообщат нам вероятность того, что изображение является реальным или поддельным, но они очень редко сообщат нам, почему они пришли к такому выводу. И даже если мы рассмотрим базовые механизмы модели, найдутся особенности, которые мы просто не сможем понять», — говорит Лю. «Между тем, все, что выводит ChatGPT, понятно людям».
Это потому, что ChatGPT основывает свой анализ только на семантических знаниях. В то время как традиционные алгоритмы обнаружения дипфейков отличают реальное от поддельного, обучаясь на больших наборах данных изображений, помеченных как реальное или поддельное, способности LLM к естественному языку дают им нечто вроде здравого смысла в понимании реальности — по крайней мере, когда они не галлюцинируют — включая типичную симметрию человеческих лиц и внешний вид реальных фотографий.
«Как только компонент зрения ChatGPT понимает изображение как человеческое лицо, компонент языка может сделать вывод, что лицо обычно имеет два глаза, и так далее», — говорит Лю. «Компонент языка обеспечивает более глубокую связь между визуальными и вербальными концепциями».
Семантические знания ChatGPT и обработка естественного языка делают его более удобным инструментом для создания дипфейков как для пользователей, так и для разработчиков, говорится в исследовании.
«Обычно мы собираем информацию об обнаружении дипфейков и преобразуем ее в язык программирования. Теперь все эти знания присутствуют в одной модели, и нам нужно только использовать естественный язык, чтобы раскрыть эти знания», — говорит Лю.
Недостатки ChatGPT
Производительность ChatGPT была значительно ниже новейших алгоритмов обнаружения дипфейков, точность которых находится на уровне середины и высоких 90-х годов.
Отчасти это связано с тем, что LLM не могут улавливать статистические различия на уровне сигнала, которые невидимы человеческому глазу, но часто используются алгоритмами обнаружения для распознавания изображений, созданных ИИ.
«ChatGPT фокусировался только на аномалиях семантического уровня», — говорит Лю. «Таким образом, семантическая интуитивность результатов ChatGPT на самом деле может оказаться палкой о двух концах для обнаружения дипфейков».
А другие LLM могут быть не столь эффективны в объяснении своего анализа. Несмотря на то, что Gemini по сравнению с ChatGPT угадывал наличие синтетических артефактов, подтверждающие доказательства часто были бессмысленными, например, указывали на несуществующие родинки.
Еще одним недостатком является то, что LLM часто отказываются анализировать изображения. На прямой вопрос, была ли фотография создана искусственным интеллектом, ChatGPT обычно отвечал: «Извините, я не могу помочь с этим запросом».
«Модель запрограммирована не отвечать, если она не достигает определенного уровня уверенности», — говорит Лю. «Мы знаем, что ChatGPT имеет информацию, относящуюся к обнаружению дипфейков, но, опять же, нужен оператор-человек, чтобы активировать эту часть его базы знаний. Оперативное проектирование эффективно, но не очень действенно, поэтому следующим шагом будет спуск на один уровень ниже и фактическая тонкая настройка LLM специально для этой задачи».
Больше информации:
Шан Цзя и др., Может ли ChatGPT обнаружить DeepFakes? Исследование использования мультимодальных больших языковых моделей для медиа-криминалистики, arXiv (2024). DOI: 10.48550/arxiv.2403.14077
arXiv
Предоставлено Университетом Буффало
Цитирование: Является ли ChatGPT ключом к предотвращению дипфейков? В исследовании выпускникам LLM предлагается обнаружить изображения, созданные ИИ (27 июня 2024 г.), полученные 28 июня 2024 г. с https://techxplore.com/news/2024-06-chatgpt-key-deepfakes-llms-ai.html.
Этот документ защищен авторским правом. За исключением любых добросовестных сделок в целях частного изучения или исследования, никакая часть не может быть воспроизведена без письменного разрешения. Содержимое предоставлено исключительно в информационных целях.